
共享PPT演讲资料(需要请自行下载)
一、爬虫
1. 爬虫解释及它的由来
解释
百科介绍:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
人话解释:人类用网络能做啥,爬虫就能干啥。
由来
2. 入门概要
2.1 什么样的爬虫是违法的

2.2 爬虫的一些规则
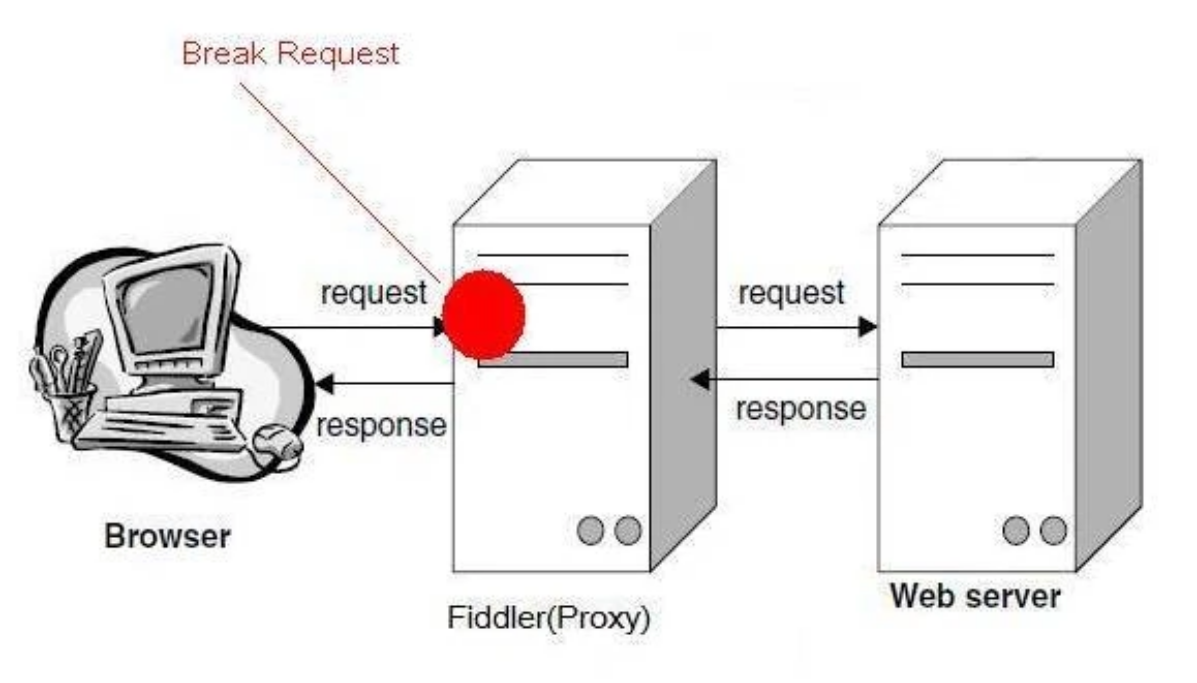
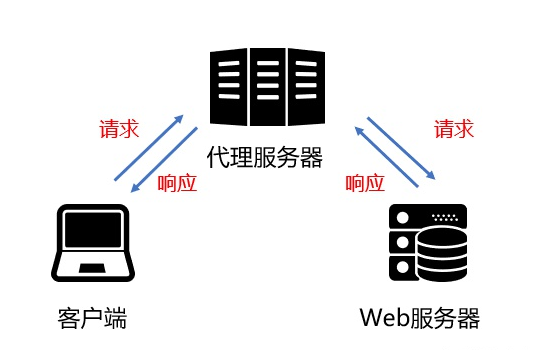
2.3 需要了解一些爬虫工具

抓包工具可以理解为是中间代理人,代理客户端发送的请求到服务器
2.4 需要了解一些常见的数据处理(加解密/摘要)算法

2.5 对语言、数据类型、网络知识的熟悉

细节拓展
2.5.1 语言
- javascript
- html
2.5.2 常见的数据树类型:
- xml
- json
2.5.3 HTTP协议的基本知识
1. 常见的HTTP请求方法:
- GET
- POST
- PUT
- DELETE
2. 响应状态码
| 状态码 | 描述 |
| 1xx消息 | 请求已被服务器接收,继续处理 |
| 2xx成功 | 请求已成功被服务器接收、理解、并接受 |
| 3xx重定向 | 需要后续操作才能完成这一请求 |
| 4xx请求错误 | 请求含有词法错误或者无法被执行 |
| 5xx服务器错误 | 服务器在处理某个正确请求时发生错误 |
3. HTTP中的Request Header了解
| 标识名称 | 描述 |
|---|---|
Cookie | 让服务器知道是谁请求的 |
User-Agent | 浏览器标识信息 |
Host | 指定请求的服务器的域名和端口号 |
Content-Type | 请求的与实体对应的MIME信息 |
Origin | 表明了请求来自于哪个站点 |
Referer | 先前网页的地址,当前请求网页紧随其后,即来路 |
4. HTTP中的Response Header了解
| 标识名称 | 描述 |
|---|---|
Location | 令客户端重定向至指定 URI |
Set-Cookie | 服务器端向客户端发送 cookie |
Content-Type | 告诉客户端实际返回的内容的内容类型 |
Expires | 包含日期/时间, 即在此时候之后,响应过期 |
5. HTTP代理
在爬取某些网站时,我们经常会设置HTTP代理IP来避免爬虫程序被封。我们获取代理 IP 地址方式通常提取国内的知名 IP 代理商的免费代理。这些代理商一般都会提供透明代理,匿名代理,高匿代理。那么这几种代理的区别是什么?我们该如何选择呢?
代理类型:
代理类型一共能分为三种。透明代理,匿名代理,高匿代理,从安全程度来说,这三种代理类型的排序是 高匿 > 匿名 > 透明。
代理类型区别:
| 代理类型 | 描述 |
|---|---|
透明代理 | 透明代理虽然可以直接“隐藏”客户端的 IP 地址,但是还是可以从来查到客户端的 IP 地址。 |
匿名代理 | 匿名代理能提供隐藏客户端 IP 地址的功能。使用匿名代理,服务器能知道客户端使用用了代理,当无法知道客户端真实 IP 地址。 |
高匿代理 | 高匿代理 高匿代理既能让服务器不清楚客户端是否在使用代理,也能保证服务器获取不到客户端的真实 IP 地址。 |
代理选择指标:
- 可用率
- 响应速度
- 稳定
- 性价比
- 安全性
使用频率;其实还有一种低成本的方法,避免爬虫程序被封,那就是常见的ADSL拨号,其稳定性高,也是一种比较有效的解决方案。
对爬虫的框架的一些认识:
需要知道的一些反爬虫策略:
- 奇奇怪怪的验证码
- 数据加解密
ip被限制
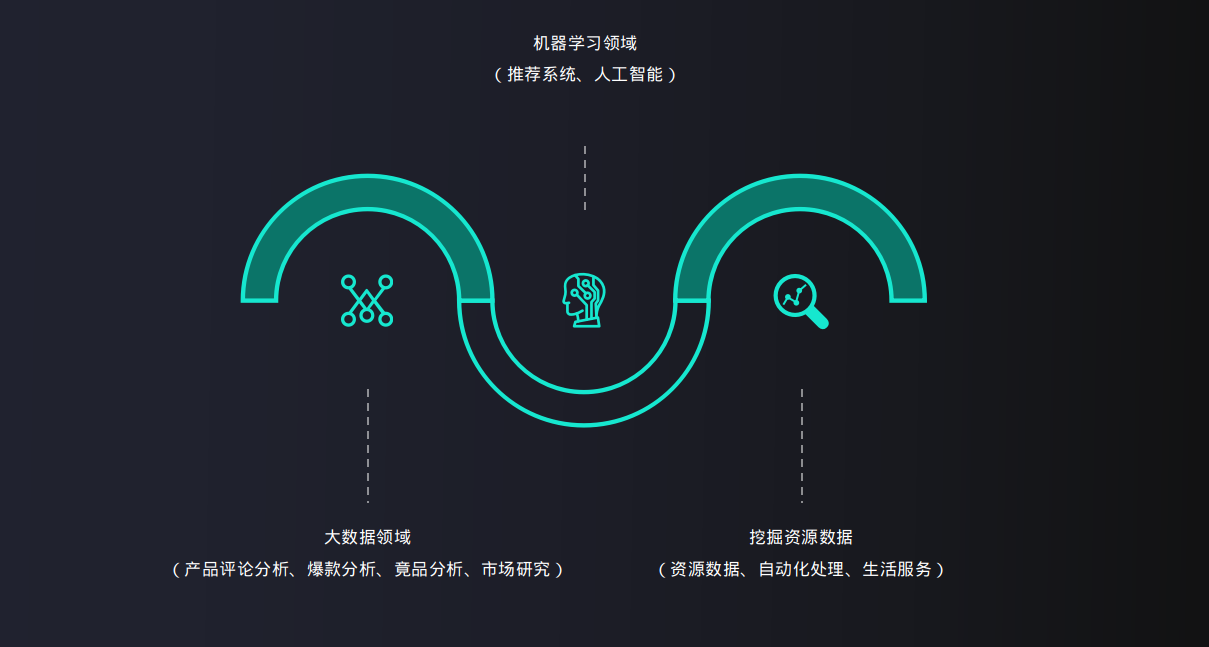
3. 爬虫应用领域
爬虫的应用领域,从广义上来说,人类用网络能做啥,爬虫就能干啥。

4. 如何爬虫
爬虫需要考虑的事情
- 需求是否可以执行
- 爬取难度
- 数据量规模
- 效率
- 性能
- 维护的成本
4.1 脚本爬虫

优点
- 采集速度快
- 占用性能低
- 不用走浏览器页面交互
缺点
- 门槛高
- 维护成本较高
4.2 可视化爬虫

细节拓展
Selenium
优点
- 免费
- 支持语言较多
- 可视化流程
- 反爬能力强
缺点
- 需要自行写代码
- 速度慢
- 占用资源较多
- 遇到大量的数据采集效率低
火车采集器
优点
- 门槛低(不用写代码)
- 可视化流程
- 可快速搭建采集系统
- 对于小量的数据采集,产出结果周期快
缺点
- 占用资源较多
- 无法进行复杂判断
- 遇到
行为校验直接凉凉 - 遇到大量的数据采集效率低
- 接口响应的数据抓取不到
- 较复杂的采集功能肯定离不了
氪金的支持
八爪鱼采集器
优点
- 门槛低(不用写代码)
- 可视化流程
- 可快速搭建采集系统
- 对于小量的数据采集,产出结果周期快
- 官方提供云采集(分布式采集)
缺点
- 占用资源较多
- 无法进行复杂判断
- 遇到
行为校验直接凉凉 - 遇到大量的数据采集效率低
- 接口响应的数据抓取不到
- 较复杂的采集功能肯定离不了
氪金的支持
4.3 场景实战
爬虫需求:某个甲方提出产品功能需要做知识产权商标检索,其需求目标是把国家知识产权局商标局中国商标网所有公开的商标数据移植到需求产品的检索功能上,其中涉及到商标图片,哪如何通过爬虫技术手段爬取呢?
笔者这里找了一个第三方网站,也能实现数据采集:点我跳转
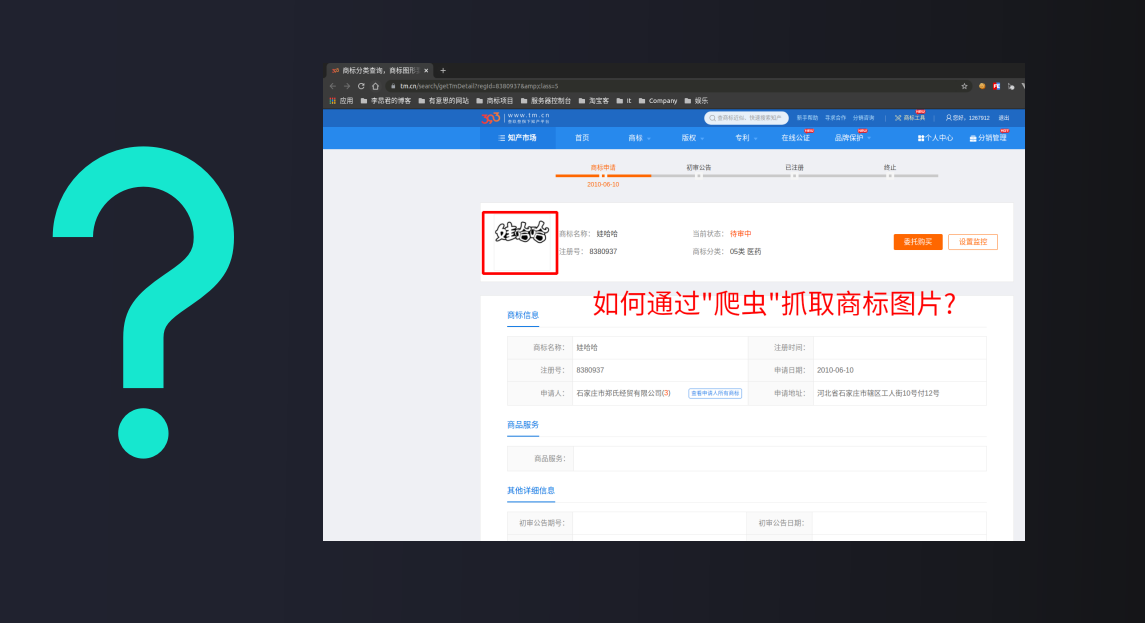
分析图片链接地址规则
链接地址:https://img.tm.cn/t/8380937.jpg

实战-脚本爬虫
实战-可视化爬虫
5. 常见爬虫遇到问题的解决方案
5.1 ip被限制

解决方案
- 接入Http代理
- ADSL重拨
- 分布式爬虫
- UserAgent轮换
- 降低抓取频率
5.2 人机校验
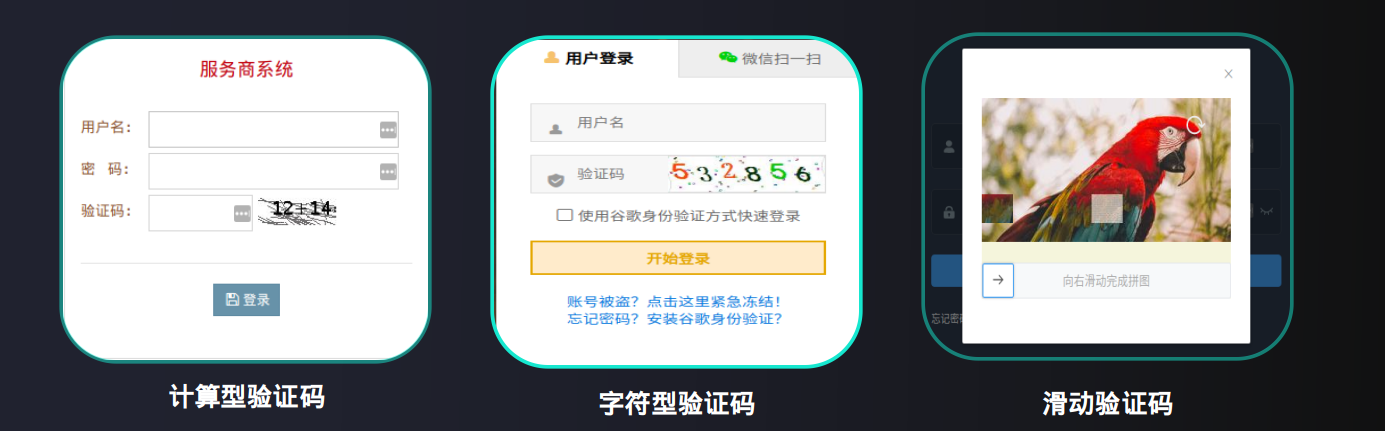
解决方案
1. 识别库制作
使用软件:完美验证码识别系统
是否收费:免费
支持平台:Windows
功能简介:
- 支持多线程并发识别,识别无需加许可
- 弄字库只能对付一些简单的码,如果复杂的码可能还是可以做的,但是识别率会比较低点,而且需要弄大量的字库
2. 卷积神经网络识别
3. 人工进入识别
4. 平台对接识别
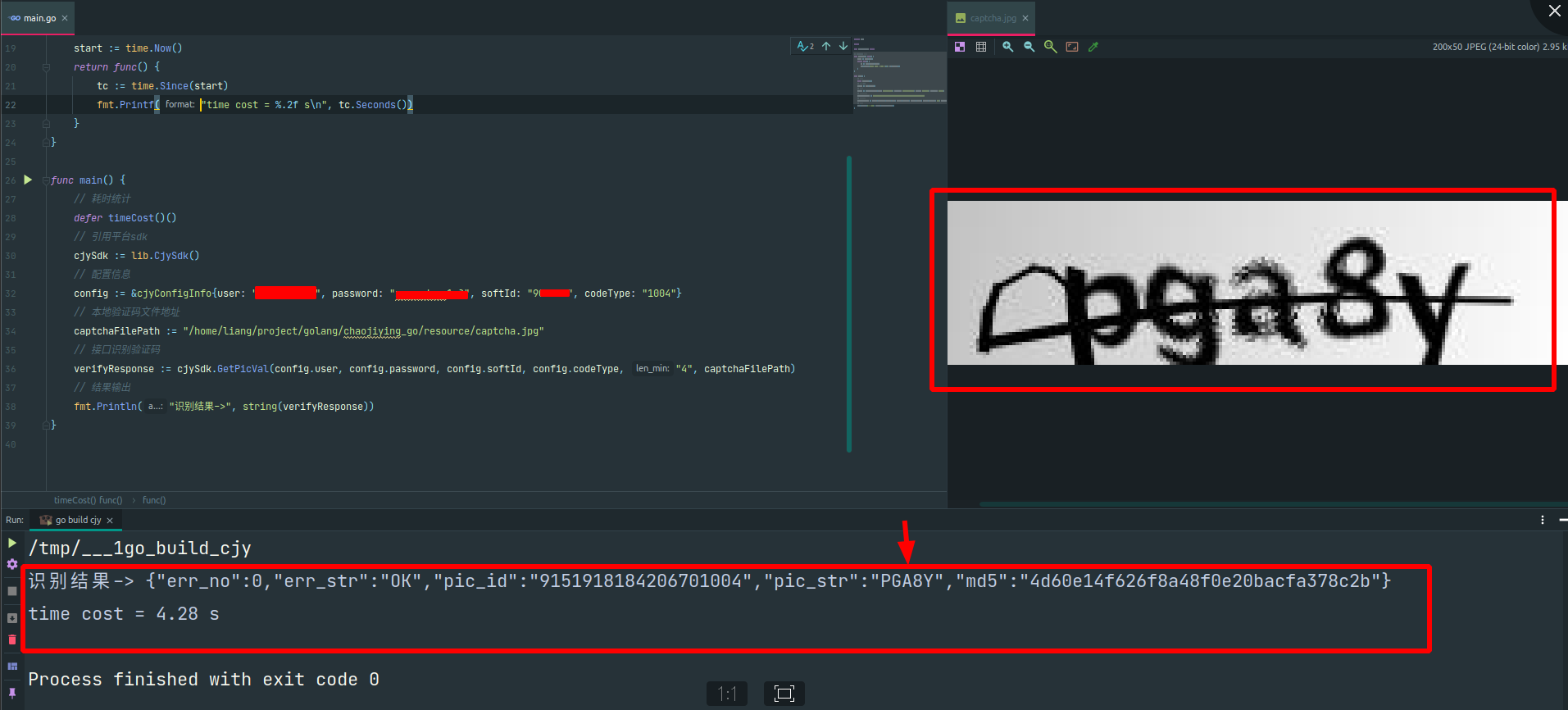
打码平台:超级鹰
字母+数字验证码,收费价格:¥0.01 /次
5. 算法识别

字符类验证码

滑块类验证码
5.3 交互数据被做了手脚

解决方案
通过浏览器中的网页调试器及配合Fd工具分析接口的交互数据方式

爬虫技术手段
- 根据关键字分析
- 断点分析
二、反爬虫
1. 为什么需要做反爬
看看这个

做反爬的好处

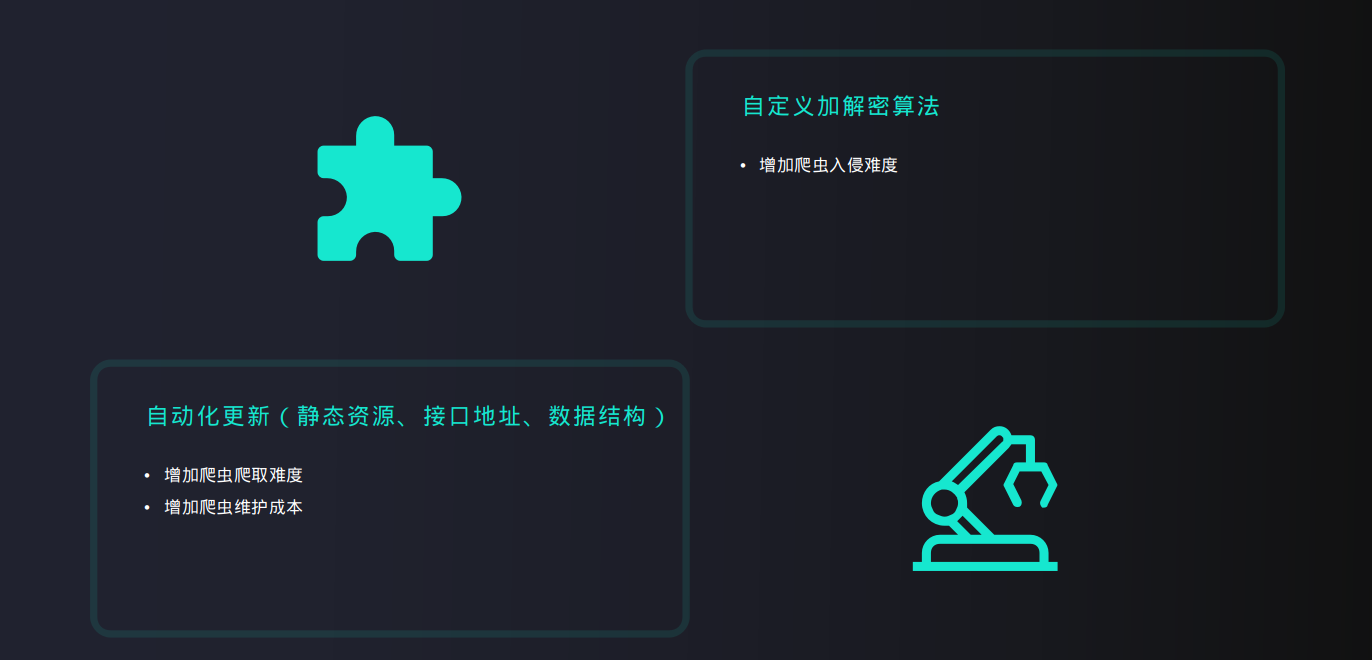
2. 如何反爬虫




三、js代码混淆
1. 为什么需要混淆代码
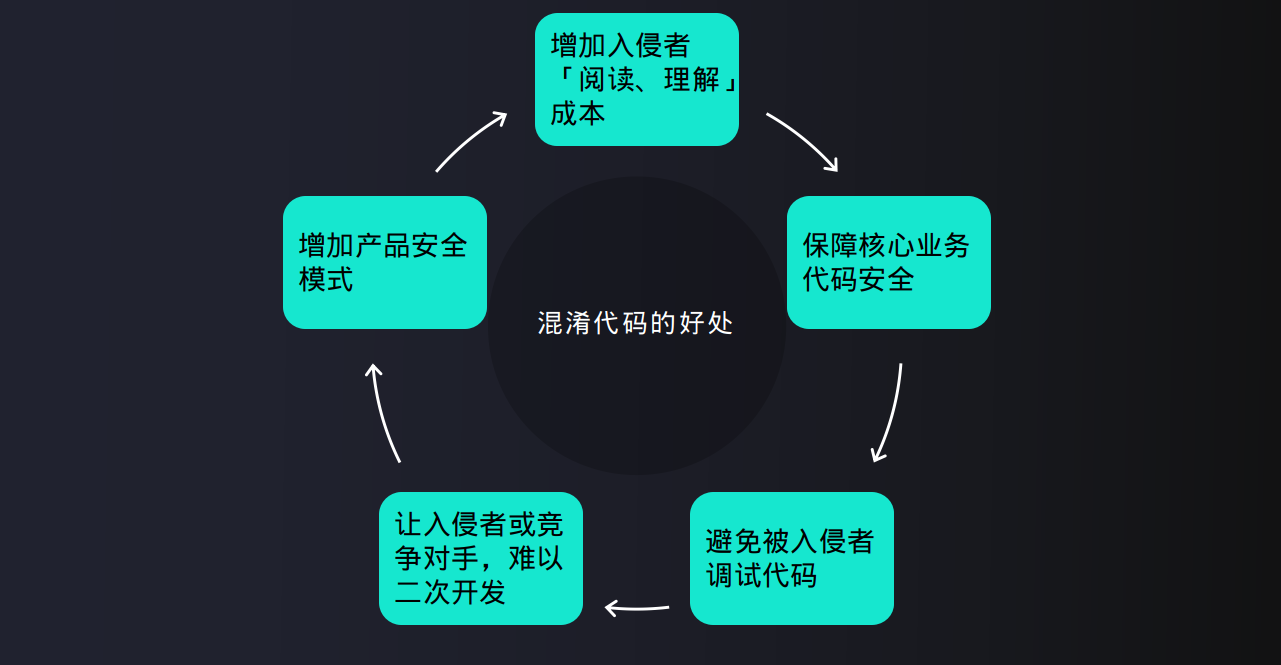
若是自己辛辛苦苦写的(商业、核心)业务代码,被其他竞争公司拿去用了或者破解了,想想都心塞。
可以从下图对比中看出两种区别:

混淆代码的好处
2. 混淆代码弊端

3. 代码保护
3.1 为什么?怎么实现?

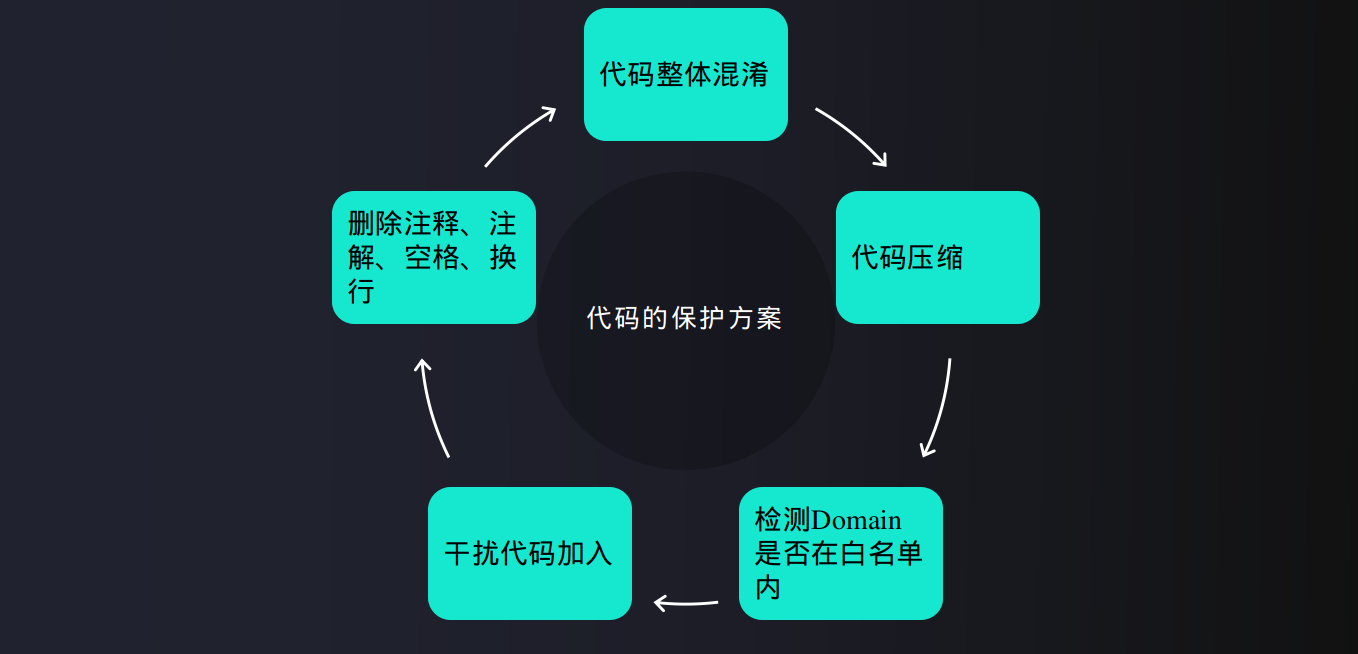
3.2 代码的保护方案
4. 混淆代码工具
4.1 JavaScript Obfuscator Tool
JavaScript Obfuscator 一个免费和高效的JavaScript混淆器。让你的代码更难复制,更开防止别人窃取你的成果。

4.2 Uglify
Uglify 是一款JS代码处理工具,提供了压缩,混淆和代码规范化等功能。

四、结语
爬虫工程师(采集)没有未来,数据工程师(采集、分析、预测)有未来。- 当下的
反爬虫场景中,没有绝对安全的保护机制,我们能做好的其实就是提高攻击者的成本。 - 对于
反爬虫未来发展方向,个人认为更多的不是依赖于算法识别而是「机器学习」识别爬虫。
